AS3与数据结构
发表于 2011年8月25日
时至今日国内外都还没有一本专讲AS3与数据结构的书,对于我这种非科班毕业的社会闲杂人等来说,入门数据结构太难了,我参考了各方代码,经过一段时间的恶补,整理了一下目前Flash开发中有可能遇得到的数据结构。完整代码在文章结尾有下载,如有错漏请直接指出谢谢。
数组
Array类应该是Flash里最常用的数据结构了。比其他语言的数组高级和灵活许多,随意装入任何数据类型,不用固定长度。
访问速度快,从后方添加(push)和删除(pop)快,但从中间或开头删除会很慢。
从100万长度的数组开头删除500个元素在我的机器上差不多要1秒钟。
var arr:Array = []
for(var i:uint= 0 ;i<1000000;i++)arr[i]=i ;
var startT:Number = getTimer()
var num:uint = 500
while(num>0)
{
arr.splice(0,1)
num--
}
trace("time:",getTimer() - startT)
但如果数组没有顺序的话,快速删除法1000个在我机器上才需要1毫秒。
var arr:Array = []
for(var i:uint= 0 ;i<1000000;i++)arr[i]=i ;
var startT:Number = getTimer()
var num:uint = 1000
while(num>0)
{
arr[0] =arr[arr.length-1]
arr.length -=1
num--
}
trace(getTimer() - startT)
Vector:Vector是Array的升级版。如果想追求效率,恰巧数组中的元素类型是固定的,或者长度是固定的,就可以将Array换成Vector类提升效率。
堆栈
堆栈是先进后出的结构,像子弹梭子一样,由于数组的push() pop()非常快,所以数组本身就是最好的堆栈。
队列
队列是先进先出,数组也可以做队列,但是从数组前端删除数据比较慢,下边10万条数据我的机器运行差不多需要2秒。
var startT:Number = getTimer()
var queue:Array = []
for(var i:int = 0 ; i<100000 ;i++)
{
queue.push(i);
}
for(var i:int = 0 ; i<100000 ;i++)
{
queue.shift()
}
trace(getTimer() - startT)
我参考as3ds改写了个链表(DLinkedList) ,实现了数组一样的 push() pop() shift() unshift() 四个方法。用这个链表只需要改一行代码,同样操作在我的机器上只要100多毫秒。
var startT:Number = getTimer()
var queue:DLinkedList = new DLinkedList()
for(var i:int = 0 ; i<100000 ;i++)
{
queue.push(i);
}
for(var i:int = 0 ; i<100000 ;i++)
{
queue.shift()
}
trace(getTimer() - startT)
这个链表是一个双向链表,可以当作各种队列也可以当作堆栈,效率都不错。
链表
这个链表实现的是一个双向链表,因为删除数据会快些,单链表优点就是省一点点内存,但删除会慢很多,用处不大,所以没有实现。
我觉得除了把链表当成队列使用,平时几乎用不到。如果非要使用就要使用Iterator了,Iterator是一种设计模式,不懂可以搜索一下。
下边是对链表所有操作的演示。
var l:DLinkedList = new DLinkedList()
l.push(1)
l.push(2)
l.push(3)
trace(l,l.head,l.tail) //[1,2,3] 1 3
l.pop()
trace(l,l.head,l.tail) //[1,2] 1 2
l.unshift(0)
trace(l,l.head,l.tail) //[0,1,2] 0 2
l.shift()
trace(l,l.head,l.tail) //[1,2] 1 2
l.push(3)
trace(l,l.head,l.tail) //[1,2,3] 1 3
//遍历,输出 1,2,3
var it:DListIterator = l.getIterator()
for(it.start() ; it.hasNext(); it.next())
{
trace(it.node.data)
}
it.start() // 索引归0
it.next()
l.remove(it) //remove 2
l.remove(it) //remove 3
trace(l,l.head,l.tail) //[1] 1 1
l.insert(it,2)
trace(l,l.head,l.tail) //[1,2] 1 2
l.insert(it,3)
trace(l,l.head,l.tail) //[1,3,2] 1 2
哈希表
哈希表应该就是Object? 在Flash里Object是动态的,赋值就 obj.abc = 123 ,删除就 delete obj.abc
var o:Object = {}
o["key"] = obj //插入
delete o["key"] //删除
如果追求Object做key可以用flash.utils.Dictionary类代替Object。
树
上边数组和链表都叫线性结构,树是典型的非线性数据结构,普通的树也不常用,但作为一个基础必须掌握,这里的树使用上边提到的双向链表存储子树。操作树要用TreeIterator,下边是演示。
var tree:Tree = new Tree(0);
var itr:TreeIterator = tree.getIterator()
itr.appendChild(1)
itr.appendChild(2)
0
/ \
1 2
itr.down()
itr.appendChild(3)
0
/ \
1 2
/
3
itr.up()
itr.appendChild(4)
0
/ | \
1 2 4
/
3
itr.childEnd()
itr.down()
itr.prependChild(5)
itr.prependChild(6)
0
/ | \
1 2 4
/ /\
3 6 5
trace(tree.dump())
上边的代码输出如下:
[TreeNode >(root) has 2 child nodes, data=room1]
+---[TreeNode > has 2 child nodes, data=room2]
| +---[TreeNode >(leaf), data=room4]
| +---[TreeNode >(leaf), data=room5]
+---[TreeNode >(leaf), data=room3]
我实现了一个toXML方法,如果把tree.toXML(tree)赋给Flex的Tree组件的dataProvider属性,就会是这个样子。
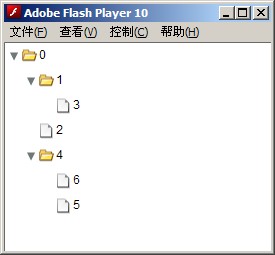
树的遍历分为前序遍历和后序遍历,演示:
代码实现看着很简单,但很需要费脑子的,是递归实现。
/**
* 前序遍历
*/
public function preorder(Node:Tree,Process:Function):void
{
Process(Node)
var itr:DListIterator = Node.children.getIterator()
while(itr.hasNext())
{
preorder(Tree(itr.node.data),Process)
itr.next();
}
}
/**
* 后序遍历
*/
public function postorder(Node:Tree,Process:Function):void
{
var itr:DListIterator = Node.children.getIterator()
while(itr.hasNext())
{
postorder(Tree(itr.node.data),Process)
}
Process(Node)
}
二叉堆与优先队列
优先队列是一种特殊的队列,它不是先入先出,而是入队的元素会自动按你指定顺序排列,先出队的永远是你指定的顺序里排最前面的。
当然这个优先队列可以用数组实现,每次入队就push后排一次序,出队pop就可以了,但是这样效率不佳,我们的优先队列是使用二叉堆实现的。
首先了解二叉树是只有2个子节点的树 ,二叉堆是一种特殊的二叉树,他的每个父节点都比子节点大。
里边用了些特殊的算法,让元素入队出队时效率更好。后边的A*寻路也用这个二叉堆来优化效率。具体算法见代码
var priorityQueue:Heap =new Heap() //新建二叉堆,默认从大到小排列
priorityQueue.enqueue(2) //入队9个数字
priorityQueue.enqueue(6)
priorityQueue.enqueue(5)
priorityQueue.enqueue(8)
priorityQueue.enqueue(7)
priorityQueue.enqueue(4)
priorityQueue.enqueue(1)
priorityQueue.enqueue(3)
priorityQueue.enqueue(9)
trace(priorityQueue) //输出9,8,5,7,6,4,1,2,3 ,发现并不是按顺序排列的
trace(priorityQueue.dequeue()) //9 但出队时就已经是排序好的了
trace(priorityQueue.dequeue()) //8
trace(priorityQueue.dequeue()) //7
trace(priorityQueue.dequeue()) //6
trace(priorityQueue.dequeue()) //5
trace(priorityQueue.dequeue()) //4
trace(priorityQueue.dequeue()) //3
trace(priorityQueue.dequeue()) //2
trace(priorityQueue.dequeue()) //1
//如果想要逆序排列,只需要提供一个compare Function,这个跟数组sort方法里的compareFunction参数一样,如下:
var f:Function = function(a:int,b:int):int{return b-a}
var p:Heap =new Heap(f)
p.enqueue(2)
p.enqueue(6)
p.enqueue(5)
p.enqueue(8)
p.enqueue(7)
p.enqueue(4)
p.enqueue(1)
p.enqueue(3)
p.enqueue(9)
trace(p.dequeue()) //1
trace(p.dequeue()) //2
trace(p.dequeue()) //3
trace(p.dequeue()) //4
trace(p.dequeue()) //5
trace(p.dequeue()) //6
trace(p.dequeue()) //7
trace(p.dequeue()) //8
trace(p.dequeue()) //9
其实Heap内部也是由数组存储的,它的算法有两个关键
1) 如何用数组储存二叉树结构
比如原树状结构为:
4
/ \
3 0
/\
1 2
则存储成数组为:[4,3,0,1,2]
2) 如何永远保持parent比child大
这点比较麻烦具体可以参考我的代码,或者找本书看看。
四叉树
四叉树通常用于2d游戏碰撞检测。假设屏幕上有500个mc,每2个之间都要进行碰撞检测,那么每一个mc都要与其他499个mc进行一次碰撞检测,那每帧总共就接近做500×500 = 250000次检测。
如果是小球还好办,用半径法,如果碰上复杂的mc需要位图碰撞检测,那每帧检测25万次flash是吃不消的。
一个优化的办法就是只与有可能碰撞的mc进行碰撞检测,这时四叉树就派上用场了。
移动鼠标会发现,只有红色的方块是有可能与鼠标拖动的方块产生碰撞的,你只要将鼠标方块与红色的方块逐个进行检测就好了,大大提升了效率
四叉树首先通过一个建树的过程将屏幕上的物体分配到,左上,右上,左下,右下四个象限中,这四个象限对应树的四个节点,每个象限还可以继续分成四个象限,根据具体情况考虑分配几层达到一个查找最快效果。
对比一下速度,下边是数组遍历,250个Sprite,两两碰撞在我机器上就惨不忍睹了。 (放上鼠标开始)
四叉树版本,500个Sprite,2倍精灵的数量两两碰撞仍然跑的流畅(放上鼠标开始)
四叉树的思想就是先屏幕分割,然后过滤出离自己很近的,有可能产生碰撞的进行碰撞检测。Flash界使用四叉树最出名的应该就是Flixel游戏引擎,它把四叉树隐藏在碰撞检测的API里,用户不需要直接操作四叉树。
调用碰撞检测的同时,引擎内部就自动建树了。大家都看到Flixel引擎的效率是非常高的,各种大小相差几倍的精灵放在一起检测也没有问题,这也是四叉树分区相比网格分区的一个优势。可惜Flixel里的四叉树
经过了各种优化,已经不是传统四叉树的样子了,很难分离出来。as3ds包里也没有四叉树的实现,所以我又google了一下,在网上看到一个写的比较清晰的JavaScript版本JavaScript QuadTree Implementation
又无意中搜到GhostCat里也有一个四叉树类,GhostCat的这个版本是我看到写的最简洁的四叉树,很是佩服作者。
不过经过研究,他们有一个共同的问题就是只能把点(point)添加到树中,这对子弹或者小球的碰撞检测还好,但通常游戏中不论是MC还是Bitmap大都是有宽高的方形。如果把他们按照点来分配进树的话,就会有漏检查的情况出现。
下图是我将上边提到的,mikechambers写的JavaScript版本转成AS3后发现的问题,mike虽然已经将压线的矩形作为有可能碰撞的对象返回,但百密一疏,由于他是按照点来分配的,始终会有漏检
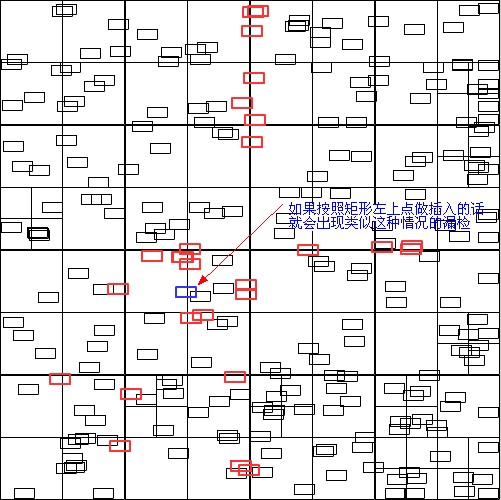
所以我又回头看Flixel里的四叉树是怎么插入的,最后综合以上所有版本,我写了我的这个四叉树类。就是上边演示的那个,代码在文章末尾下载包里,太长就不贴了,我记得应该是写了很多注释。大家可以研究讨论一下。
图
图由节点node和指针arc组成,图的遍历与树差不多,分为广度优先遍历(与树的后序遍历),和深度优先遍历(与树的前序遍历)。
图在游戏中通常用作保存地图,网上流行的页游地图都是tilemap的,区块其实就是简化了指针之后的图,所以他们的理论是相通的。
请看基于图的A*算法演示:
因为我用了Adobe kuler配了一下色,所以漂亮了许多 :)
QuadTree_collition
为什么要用A*寻路而不是广度或深度遍历寻路呢?因为他们本身是很傻很执着的,由于不知道终点位置而盲目扫描整个图,这会浪费效能,而A星之所以叫做启发式寻路,是因为它事先预测了终点的大概方向而向那个方向扫描,这样增加了效率。
我是照着这篇很有名的A Star入门教程写的代码:A*寻路初探
因为他是基于区块的,所以要改动一下,而需要改变的只有一个地方,他的文章里是循环检查 周围相邻的8格 ,而我们改成 连通的所有节点 就ok了。
我的Astar类已经按照教程逐句做了注释,对照教程应该很容易理解了。
与教程不同的地方就是:
1) 我使用了上边提到Heap优先队列来优化了open列表,使F值最小的始终在列表最上方,这个在教程后边也有讲。
2)改用了 距离的启发值函数 计算H值,而原教程使用的 曼哈顿距离启发值函数 也有提供,可以替换,只是貌似没有距离的效果好,大家可以自己试一下。
package examples.Astar
{
import ds.Graph;
import ds.GraphArc;
import ds.GraphNode;
import ds.Heap;
public class Astar
{
/**
* 距离启发函数
*/
public static function distance(startNode:GraphNode,endNode:GraphNode):Number
{
return Math.sqrt( (endNode.data.x - startNode.data.x)*(endNode.data.x - startNode.data.x) + (endNode.data.y - startNode.data.y)*(endNode.data.y - startNode.data.y))
}
/**
* 曼哈顿启发函数
*/
public static function manhattan(startNode:GraphNode,endNode:GraphNode):Number
{
return Math.abs(endNode.data.x - startNode.data.x)+Math.abs(endNode.data.y - endNode.data.y);
}
/**
* 寻路
*/
public static function find(graph:Graph , startIndex:int,endIndex:int):Array
{
//还原值
for each (var n:AstarNode in graph.nodes)
{
n.f = n.g = n.f = 0
n.parent = null
}
//根据f值升序排列
var open:Heap = new Heap(function(a:AstarNode,b:AstarNode):Number{return b.f - a.f});
var close:Array = []
//1,把起始节点添加到开启列表。
AstarNode(graph.getNode(startIndex)).f = 0
open.enqueue(graph.getNode(startIndex));
//2,重复如下的工作:
while(open.heap.length>0)
{
//a) 寻找开启列表中F值最低的节点。我们称它为当前节点。
var cur:AstarNode = AstarNode(open.dequeue())
if(cur==graph.getNode(endIndex))return Astar.getPath(cur)
//把目标格添加进了关闭列表,这时候路径被找到
//b) 把它切换到关闭列表。
close.push(cur)
//c) 对相邻的格中的每一个?
for each(var i:GraphArc in cur.arcs)
{
var test:AstarNode = AstarNode(i.targetNode)
//如果它不可通过或者已经在关闭列表中,略过它。
if(close.indexOf(test)>=0)continue
//如果它不在开启列表中,把它添加进去。
//把当前格作为这一格的父节点。记录这一格的F,G,和H值。
if(open.heap.indexOf(test)<0)
{
test.parent =cur
test.g = cur.getArc(test).weight
test.h = Astar.distance(test,graph.getNode(endIndex))
// 这里使用距离启发值,原教程使用的曼哈顿启发函数
//可以替换成这句 Astar.manhattan(test,graph.getNode(endIndex))
test.f = test.g + test.h
open.enqueue(test);
}else
{
//如果它已经在开启列表中,用G值为参考检查新的路径是否更好。
//更低的G值意味着更好的路径。
//如果是这样,就把这一格的父节点改成当前格,并且重新计算这一格的G和F值。
//如果你保持你的开启列表按F值排序,改变之后你可能需要重新对开启列表排序。
if( cur.g+ cur.getArc(test).weight < test.g)
{
test.parent = cur
test.g = cur.g+ cur.getArc(test).weight
test.f = test.h+test.g
open.modify(test,test);
}
}
}
}
return []
}
public static function getPath(node:AstarNode):Array
{
var arr:Array = [node]
while(node.parent)
{
arr.push(node.parent)
node = node.parent
}
return arr
}
}
}
以上就是我目前了解到的对于flash开发还比较实用的数据结构了,欢迎补充,以供我继续学习。
我的版本很多方法都是直接抄自as3ds ,有些方法却改成比较容易理解的方式,提供的方法也少很多,仅供学习参考.
本文采用 署名-禁止演绎 4.0 国际许可协议 (CC BY-ND 4.0) 进行许可(保留链接可任意转载,禁止修改)。留言系统需要代理访问